About cluster computing¶
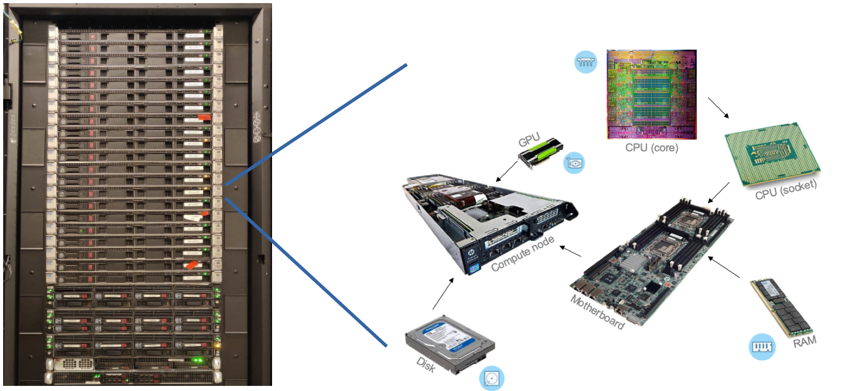
The CISM manage several compute clusters. A cluster is a made of computers (nodes) that are interconnected and appear to the user as one large machine. The cluster is accessed through a login node (or frontend node) where users can manage their jobs and data in their home directory. Each compute node has a certain number of processors, a certain amount of memory (RAM) and some local storage (scratch space). Each processor comprises several independent computing units (cores), and possibly several accelerators (GPUs). In a hardware context, a CPU is often understood as a processor die, which you can buy from a vendor and fits into a socket on the motherboard, while in a software context, a CPU is often understood as one compute unit, a.k.a. a core. All the resources are managed by a Resource Manager/Job Scheduler to which users must submit batch jobs. The jobs enter a queue, and are allocated resources based on priorities and policies. The resource allocation is exclusive, meaning that when a job starts, it has exclusive access to the resources it requested at submission time.
The software installed on the clusters to manage resources is called Slurm ; an introductory tutorial can be found here.
The CISM operates two clusters: Lemaitre and Manneback. Lemaitre was named in reference of Georges Lemaitre (1894–1966), a Belgian priest, astronomer and professor of physics at UCLouvain. He is seen by many as the father of the Big Bang Theory but also he is the one who brought the first supercomputer to our University.
Manneback was named after Charles Manneback (1894-1975), Professor of Physics at UCLouvain. Close friend to Georges Lemaitre, he was the lead of the FNRS-IRSIA project to build the first supercomputer in Belgium in the 50’s.
You can see Manneback (left) and Lemaitre (right) in the picture below, picture that was taken during a visit of Cornelius Lanczos (middle) at Collège des Prémontrés in 1959 (click on the image for more context).

Besides Lemaitre and Manneback, and thanks to various collaborations (CÉCI, EuroHPC, Cenaero and PRACE), CISM users can access more clusters, of multiple sizes. Clusters are organised according to their size into three categories:
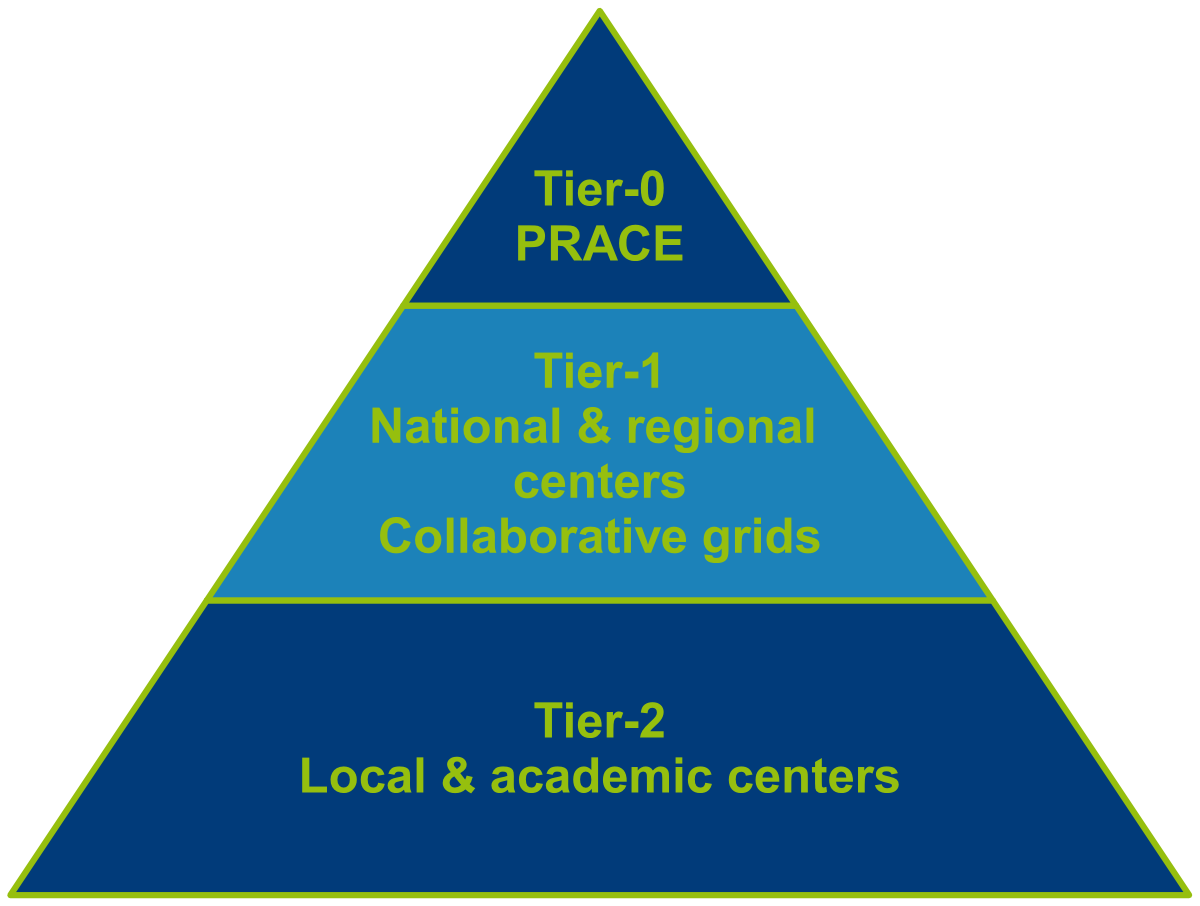
The general rule is that access to a higher-up category Tier-N is conditioned on being able to demonstrate proper abilities in the Tier-(N+1) category.
Access & conditions¶
- access to Tier-2 clusters is granted automatically to every member of the University, a CÉCI account must be requested;
- access to Tier-1 clusters requires the submission of a Tier-1 project and a valid CÉCI account ;
- access to Tier-0 clusters requires responding to call for EuroHPC proposals and a valid UCLouvain portal account ;
Note that while usage of the clusters is free, users are encouraged to contribute by requesting computing CPU.hours in their scientific project submissions to funding agencies and users are requested to tag their publications that were made possible thanks to the CISM/CÉCI infrastructure.
List of clusters¶
| Cluster name | Funding | Size | Hosting institution | More information |
|---|---|---|---|---|
| Manneback | CISM users | Tier-2 | UCLouvain | This page |
| Lemaitre4 | CÉCI | Tier-2 | UCLouvain | https://www.ceci-hpc.be |
| Lyra | CÉCI | Tier-2 | ULB | https://www.ceci-hpc.be |
| NIC5 | CÉCI | Tier-2 | ULiège | https://www.ceci-hpc.be |
| Hercules | CÉCI | Tier-2 | UNamur | https://www.ceci-hpc.be |
| Dragon2 | CÉCI | Tier-2 | UMons | https://www.ceci-hpc.be |
| Lucia | Walloon Region | Tier-1 | Cenaero (Gosselies) | https://tier1.cenaero.be/fr/LuciaInfrastructure |
| Lumi | EuroHPC | Tier-0 | CSC (Finland) | https://docs.lumi-supercomputer.eu/hardware/ |
Lemaitre¶
The Lemaitre4 cluster is a CÉCI clusters and is shared among all CÉCI users, by contrast with Manneback, which is a UCLouvain-only machine. Consequently, all documentation regarding Lemaitre will be found on the CÉCI documentation website.
As the name implies, Lemaitre4 is the third generation of Lemaitre
cluster. Below is a summary of the cluster resources as output by sinfo.
[dfr@lm4-f001 ~]$ sinfo
Partitions:
batch* (2days)
Nodes:
#Nodes Partition CPU S:C:T CPUS Memory GPUs
40 batch* AMD,Genoa,9534 2:64:2 256 748G (null)
Filesystems:
Filesystem quota
$HOME 100G
$GLOBALSCRATCH unlimited
$CECIHOME 100.0GB
$GLOBALSCRATCH unlimited # 318TB available
More information available on the CÉCI website
Manneback¶
Manneback is a cluster built with hardware acquired progressively thanks to multiple funding solutions brought by CISM users. It is configured for most aspects just like the CÉCI clusters so the CÉCI documentation mostly applies for Manneback as well.
Note
The following assumes a basic knowledge of Slurm
Available hardware¶
While CÉCI clusters are mostly homogeneous, Manneback is made of several different generations of hardware.
Use the sinfo command to learn about the available hardware on Manneback:
Partitions:
Def* (5days) keira (5days) qclong (5days) pauli (5days) pelican (5days) cp3 (5days) gpu (2days)
Nodes:
#Nodes Partition CPU S:C:T CPUS Memory GPUs
16 cp3 CascadeLake,Xeon,4214 2:24:1 48 187.4G
8 cp3 Genoa,EPYC,9454 1:96:1 96 377.6G
1 cp3 Genoa,EPYC,9454P 1:96:1 96 377.4G
11 cp3 Genoa,EPYC,9454P 1:96:1 96 377.6G
1 cp3 Rome,EPYC,7452 2:32:2 128 503.6G
8 cp3 Rome,EPYC,7452 2:64:1 128 503.5G
8 cp3 Rome,EPYC,7452 2:64:1 128 503.6G
19 cp3 SkyLake,Xeon,4116 2:24:1 48 187.4G
2 cp3 Westmere,Xeon,X5675 2:1:1 2 7.8G
1 Def* Milan,EPYC,7763 2:64:1 128 1T
1 gpu CascadeLake,Xeon,5217,Tes 2:8:1 16 377.4G TeslaV100:2
1 gpu CascadeLake,Xeon,5217,Tes 2:8:2 32 377.4G TeslaV100:2
1 gpu CascadeLake,Xeon,6244,GeF 2:8:2 32 376.4G GeForceRTX2080Ti:6
1 gpu Genoa,EPYC,9354P,Tesla,Te 1:32:1 32 377.6G TeslaL40s:4
1 gpu Genoa,EPYC,9354P,Tesla,Te 1:32:2 64 377.4G TeslaL40s:4
1 gpu IceLake,Xeon,6346,Tesla,T 2:16:2 64 251.3G TeslaA10:4
1 gpu Milan,EPYC,7313,Tesla,Tes 2:16:2 64 251.5G TeslaA100:2
2 gpu Milan,EPYC,7313,Tesla,Tes 2:16:2 64 251.7G TeslaA100_80:2
2 gpu Rome,EPYC,7302,Tesla,Tesl 2:16:2 64 503.6G TeslaA100:2
1 gpu Rome,EPYC,7352,GeForce,Ge 2:24:2 96 503.6G GeForceRTX3090:4
1 gpu SkyLake,Xeon,6346,TeslaA1 2:16:2 64 251.5G TeslaA10:4
16 keira Milan,EPYC,7763 2:64:2 256 1T
2 keira Rome,EPYC,7742 2:64:2 256 251.5G
4 keira Rome,EPYC,7742 2:64:2 256 503.6G
1 pauli Milan,EPYC,7313 2:16:2 64 1T
3 pelican IceLake,Xeon,6326 2:16:2 64 251.3G
1 qclong Genoa,EPYC,9354 2:32:1 64 1.5T
4 qclong Genoa,EPYC,9354 2:32:1 64 377.6G
Filesystems:
Filesystem quota
$HOME 100G
$GLOBALSCRATCH 10T
$CECIHOME 100.0G
$GLOBALSCRATCH unlimited
Multiple CPU and GPU vendors and generations are represented. The
Features column in the above list shows the CPU code name, the CPU family
(Xeon is Intel’s server CPU brand, EPYC is AMD’s) and the CPU reference. For
GPU nodes, the column also contains the GPU series and type.
The CPU code name is representative of the generation of the CPU (from older to more recent):
- Intel: Nehalem > Westmere > SandyBridge > IvyBridge > Haswell > Broadwell > SkyLake > CascadeLake > IceLake
- AMD: K10 > Zen > Rome > Milan > Genoa
In your submission script, you can select one or more specific features with
the --constraint= option, like --constraint="Nehalem|Westmere"
for instance to choose a compute node with an older CPU. The --constraint option accepts quit complex expressions, you can find the documentation here.
Another distinctive feature of Manneback is that some nodes are equiped with GPUs. They are listed in the last column as a GPU name followed by the number of GPUs in each node.
As for CPUs multiple generations are available, in chronological order:
- nVidia: TeslaM10 > TeslaV100 (Volta) > GeForceRTX2080Ti (Turing) > TeslaA100, GeForceRTX3090, TeslaA10 (Ampere) > L40s (AdaLovelace)
The GPU’s are considered a “generic resource” in Slurm, meaning that you
can reserve the GPU for your job with a command like --gres="gpu:TeslaV100:2"
in your submission script. This would request two V100 GPUs. If you do not need to choose a particular type of GPU, you can also simply request --gres=gpu:1 for instance for just one GPU.
The --gres (documentation) option will allow you to request a number of GPUs per node. You can also use --gpus (documentation) option
to request a total number of GPUs per job and not per node.
The --gres and --gpus options do not allow as much flexibility as the --constraint. Therefore, we also define features related to GPUs, such as Testla, Tesla100, Geforce, etc. You can thus specify
--gpus=1
--constraint=Tesla
to request one Tesla GPU if you do not care about the difference between a TeslaV100 and a TeslaA100.
Warning
Beware that the demand for GPUs is very high so jobs that request a GPU but let it sit idle for long periods will be cancelled.
As GPU resources are much scarcer that CPU resources, GPUs will impact the fairshare much more than CPUs, depending on the performance of the GPU and the ratio of CPUs to GPU on the compute nodes.
Partitions¶
The nodes are organised into partitions, which are logical sets of nodes with either similar hardware or similar policies/configurations.
Multiple CPU partitions are available on Manneback: The default one (Def) which is opened to everyone,
cp3, which is open to everyone but CP3 users have a higher priority there, keira which is open to everyone but NAPS users have a higher priority there, and pelican which is also open to everyone but mainly to ELIC users. The GPU nodes are grouped into the gpu partition.
Note that you can specify
#SBATCH -–partition=Def,cp3 to submit a job that will run on the
earliest available partition.
Quality of Service¶
A Quality Of Service (QOS) is a parameter that a job can request to bring specific privileges for the job, for instance a higher priority, or a longer run time. A QOS is typically granted to department/groups who participate in the funding of the Manneback hardware.
Currently, the following QOS’es are defined and available on the respective partitions for the listed groups:
| QOS | Type | Partition | Group |
|---|---|---|---|
cp3 |
higher priority / longer jobs | cp3 |
CP3 |
keira |
higher priority | keira |
MODL |
interactive |
higher priority but limited nb of jobs/job duration | gpu |
ELEN,MIRO,CP3 |
preemptible |
longer job, more jobs, but preemptible (killable) jobs | gpu |
Everyone |
A QOS is chosen in Slurm with `--qos=.... For instance, to use the interactive QOS, add #SBATCH --qos=interactive in your submission script.
Note
Beware that QOS are not automatically granted to users; users must request access to them explicitely by email to the administrators.
The cp3 and keira QOS’es bring a higher priority for jobs on the partitions that their corresponding groups funded.
The configuration of the GPU partition is specific and was designed in order to make interactive jobs and production jobs run as smoothly as possible together on that partition.
By default, a job submitted to the GPU partition will be subjected to the following restrictions: maximum two jobs running at all times, for a maximum duration of 2 days. To run more jobs and/or longer jobs, users must use the preemptible QOS, that will allow up to 30 5-days-long jobs. The drawback is that those jobs will be preemptible, meaning that they can potentially be stopped by Slurm to let a higher-priority job run immediatley. As a consequence,
Warning
jobs submitted with the preemptible QOS must then be checkpoint/restart-enabled.
The interactive QOS will allow 1 9-hour-long job with a very high priority per user, intended for interactive jobs running during the day.
Disk space¶
Every user has access to a home directory with a 100GB quota.
A global scratch $GLOBALSCTACH (/globalscratch) is available, offering a 200TB space NFS mounted on all
the compute nodes. There is no quota enforced on that filesystem ; it is the responsibility of the users to remove the files that are not needed anymore by any job. This space is cleaned periodically.
Warning
The scratch space is not suitable for long-term storage of data.
Each node furthermore has a local /scratch space. Local scratch is a smaller file system directly attached to the worker node. It is created at the beginning of a job and deleted automatically at the end. Again here no quota is enforced, but the available space is limited by the hardware.
Connection and file transfer¶
Clusters are accessed with your CÉCI login and SSH key. Refer to the CÉCI documentation for more details. Access to Manneback is achieved by pointing your SSH client to manneback.cism.ucl.ac.be with your CÉCI login and SSH key.
Do not hesitate to use the SSH configuration wizard if you are using the command line SSH client. Manneback will be automatically configured for you.
First connection warning¶
When you connect for the first time, the SSH client will ask you to confirm the identity of the remote host, you can do so by verifying that the fingerprint shown to you is among the ones listed below:
Frontend 1:
SHA256:Q3IYMwb5QElBkqmVbJyi8UgFoyKZMZQsWRRU3CEvV8sSHA256:iR1HQsjGvKxo4uwswD/xLepW6DA3e45jUbNEZTntWRcSHA256:i2Hb6HDaeMz6h99/qHu3lIqGUX6Zrx8Yuz0ELTQzsjc
Frontend 2
SHA256:Q3IYMwb5QElBkqmVbJyi8UgFoyKZMZQsWRRU3CEvV8sSHA256:iR1HQsjGvKxo4uwswD/xLepW6DA3e45jUbNEZTntWRcSHA256:i2Hb6HDaeMz6h99/qHu3lIqGUX6Zrx8Yuz0ELTQzsjc
User self-assessment test¶
Users must pass a simple test to use Manneback. The test is very short (5 questions) and easy; 5 minutes should be enough. It exists only to make sure every one uses the cluster in the intended way and does not harm other users’ experience on the cluster. New users have a few weeks to pass the test voluntarily before the test is enforced upon login. This is recalled upon every login in the message of the day.
To start the test, you simply run selftest.py. As soon as you respond correctly to the questions, the message will disappear. As a hint, each question contains a link to the corresponding section in the documentation.
Installed software¶
Many software are installed on the clusters and are available in multiple versions. Those versions are managed with modules.
You are welcome to install software in your home directory, but beware that
host-specific optimisation options for compilers on the frontend might generate software that is unsuitable for other generations of CPUs
and Conda-based installations generate very large amounts of small files that make the whole system less performant, do not use them if possible. Also, you will not be able to install software with a system-wide package manager such as apt or yum/dnf and will not be able to run command as root with sudo as you can see in many tutorials. These approaches are not meant for multi-user clusters offering multiple version of each software.
The preferred way of installing software is with Easybuild. If the software is useful to multiple users, feel free to contact us to install it globally on the cluster.
Job submission¶
All clusters run the Slurm workload manager/scheduler. A detailed introduction is available on the CÉCI website, and a video can be found on our Youtube channel.
About the cost¶
Access to the computing facilities is free of charge. Usage of the equipment for fundamental research is free since 2017 for most researchers with a normal usage.
Note
Although access is free, the acquisition model of the hardware for Manneback is solely based on funding brought by users.
However, we encourage users who foresee a large use of the equipment for a significant duration to contact us and include budget for additional equipment in their project funding requests. When equipment is acquired thanks to funds brought by a specific group, the equipment is shared with all users but the funding entity can obtain exclusive reservation periods on the equipment or request specific configurations.
If the expected usage does not justify buying new equipment, but the project’s budget include computation time, the CISM can also bill the usage of the equipment for the duration of the project. Rates vary based on the funding agency (European, Federal, Regional, etc.) and the objective of the research (fundamental, applied, commercial, etc.)
Before 2017, if a research group (pôle de recherche) usage exceeded 200.000 hCPU (CPU hours), equivalent to the usage of 23 processors during a full year, the cost was computed as a function of the yearly consumption as follows:
Rate applied in 2016 related to you research group consumption in 2015:
- Below 200.000 hCPU: 0 €/hCPU
- Between 200.000 and 2.500.000 hCPU: 0.00114 €/hCPU
- Over 2.500.000 hCPU: 0.00065 €/hCPU
For 2017 and beyond, thanks to a participation by the SGSI in the budget of the CISM, the cost will be null for the users who do not have specific funding for computational resources. Users funded by a Regional, Federal, European or Commercial project with specific needs should contact the CISM team for a quote.